One of the main challenges in training a single agent on many tasks at once is scalability. Since the current state-of-the-art methods like A3C (Mnih et al., 2016) or UNREAL (Jaderberg et al., 2017b) can require as much as a billion frames and multiple days to master a single domain, training them on tens of domains at once is too slow to be practical. This paper introduces a new distributed agent IMPALA (Importance Weighted Actor-Learner Architecture) that not only uses resources more efficiently in single machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. It achieve stable learning at high throughput (much faster wall-clock time) by combining decoupled acting and learning with a novel off-policy correction method called V-trace.
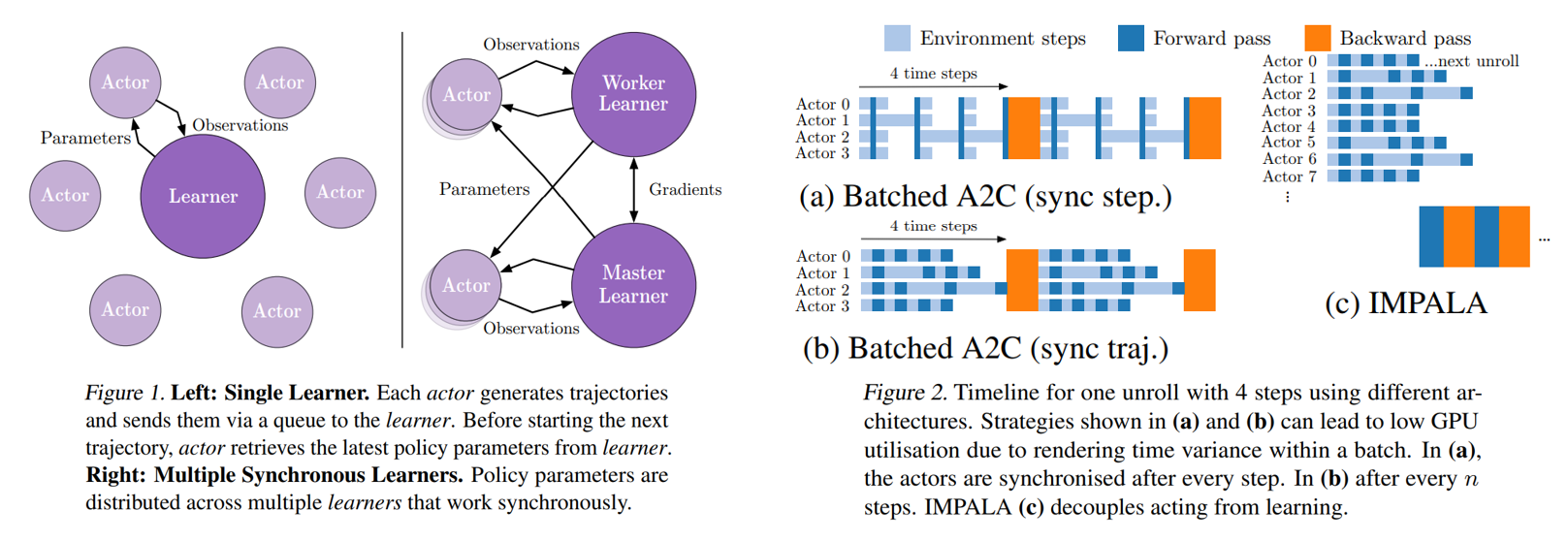
Unlike the popular A3C-based agents, in which workers communicate gradients with respect to the parameters of the policy to a central parameter server, IMPALA actors communicate trajectories of experience (sequences of states, actions, and rewards) to a centralised learner. Since the learner in IMPALA has access to full trajectories of experience we use a GPU to perform updates on mini-batches of trajectories while aggressively parallelising all time independent operations. This type of decoupled architecture can achieve very high throughput. However, because the policy used to generate a trajectory can lag behind the policy on the learner by several updates at the time of gradient calculation, learning becomes off-policy. Therefore, we introduce the V-trace off-policy actor-critic algorithm to correct for this harmful discrepancy. With the scalable architecture and V-trace combined, IMPALA achieves exceptionally high data throughput rates of 250,000 frames per second, making it over 30 times faster than single-machine A3C.
URL: arxiv.org/abs/1802.01561
Author: DeepMind
Topic: Distrubuted Learning
Video: www.youtube.com/watch?v=kOy49NqZeqI
Refer to the video above, for further explanation.
2. IMPALA
IMPALA uses an actor-critic setup to learn a policy $\pi$ and a baseline function $V^\pi$. The process of generating experiences is decoupled from the learning of parameters for $\pi$ and $V^\pi$. The architecture consists of a set of actors, repeatedly generating trajectories of experience, and one or more learners that use the experiences sent from actors to learn $\pi$ off-policy.
At the beginning of each trajectory, an actor updates its own local policy µ to the latest learner policy $\pi$ and runs it for n steps in its environment. After n steps, the actor sends the trajectory of states, actions and rewards $(x_1, a_1, r_1), . . . , (x_n, a_n, r_n)$ together with the corresponding policy distributions $µ(a_t|x_t) $ and initial LSTM state to the learner through a queue. The learner then continuously updates its policy $\pi$ on batches of trajectories, each collected from many actors. This simple architecture enables the learner to be accelerated using GPUs and actors to be easily distributed across many machines. However, the learner policy $\pi$ is potentially several updates ahead of the actor’s policy µ at the time of update, therefore there is a policy-lag between the actors and learner. V-trace corrects for this lag to achieve extremely high data throughput while maintaining data efficiency. It lower communication overhead than A3C since the actors send observations rather than parameters/gradients.
'Deep Learning > 강화학습' 카테고리의 다른 글
| [2017.05] Constrained Policy Optimization (0) | 2021.04.25 |
|---|---|
| [2018.03] Policy Optimization with Demonstration (0) | 2021.04.23 |
| [2017.05] Curiosity-driven exploration by self-supervised prediction (0) | 2021.04.17 |
| [2018.11] Recurrent experience replay in distributed reinforcement learning (0) | 2021.04.16 |
| [2017.07] Hindsight Experience Replay (0) | 2021.04.16 |



