이 논문은 이미 학습한 Model을 가져와서, 후처리로 손실을 최소화 하는 선에서 Channel Pruning을 하는 방법입니다. 코드는 Caffe로 되어 있어서, 지금 보기에는 쉽지 않고, 실험 결과 역시 지금 상황에서는 큰 의미 없어 보입니다. 그렇지만, 뒤에서 다룰 AMC: AutoML for Model Compression and Acceleration on Mobile Devices 논문에 1저자의 논문이여서 읽어보게 되었습니다.
URL: https://arxiv.org/abs/1707.06168
Code: https://github.com/yihui-he/channel-pruning
1. Algorithm

점선의 박스에서, Feature Map "B"에서 두개의 Channel이 Pruning될 수 있다면, 뒤에 있는 Weight "W"의 두 개 Channel과 앞에 있는 Weight 중, 2개의 Filter를 동시에 제거할 수 있을 것 입니다. 이러한 Channel Pruning의 특성으로 인해, Weight Pruning(Random Pruning)과 달리 Strucutural Pruning이라고도 불립니다.
1.1 Define L1(LASSO) optimization problem
일반적인 Channel Pruning 논문들이 (i.e. Learning structured sparsity in deep neural networks), 학습 시에 L1(Lasso) Sparsity Regularization을 사용하여 Channel Pruning을 Training시에 해결하려고 합니다. 하지만 이 논문에서는 이미 학습된 모델을 가져와서, 아래의 최적화 식을 적용하여 후처리 Channel Pruning을 구현한다는 차이점이 있습니다.
하나의 Layer를 기준으로 생각할 시, Pruning한 X와 W의 Convolution의 값과 원래의 Output Y의 차이가 최소로 되게 하는 최적화 문제로, 논문에서는 이게 NP-hard 문제라고 합니다. 이를 해결하기 위해 아래 2)와 3)의 방법을 Iterative하게 반복한다고 합니다.

1.2 Select Channel to Remove in "B" (beta)
(2)의 식에서 먼저 W를 고정하고 beta에 대해서 아래와 같이 먼저 최적화 한다고 합니다(feat. LASSO Regression)
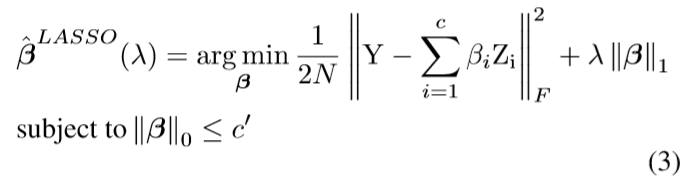
위 문제를 풀면, beta 값을 구할 수 있는데, beta_i가 0인 경우에는 해당 Channel이 Pruning됨을 나타냅니다.
1.3 Minimize Reconstruction Error after Pruning
아래의 최적화 식을 통해 Reconstruction Error를 다시 복원시키는 방향으로 W를 다시 구한다 정도로 이해하면 될 것 같습니다. 2)에서는 W를 고정하고, beta에 대해서 최적화를 진행했다면 3)에서는 beta를 고정하고 W에 대한 최적화를 진행합니다.

1.4 Iterating Two Step(2, 3) for convergence
논문을 읽어보면, 역시나 Finetuning해야 될 것들이 많아보이고, ResNet계열에도 적용을 해보았다고는 하나, 실제로 사용하게 될 일은 거의 없을 것 같습니다.


