이 논문은 기존의 Heuristic한 방법의 Model Compression 방법 대신, 강화학습을 사용하여 자동화 되었지만 더 좋은 성능의 Model Compression을 달성하였다고 합니다.
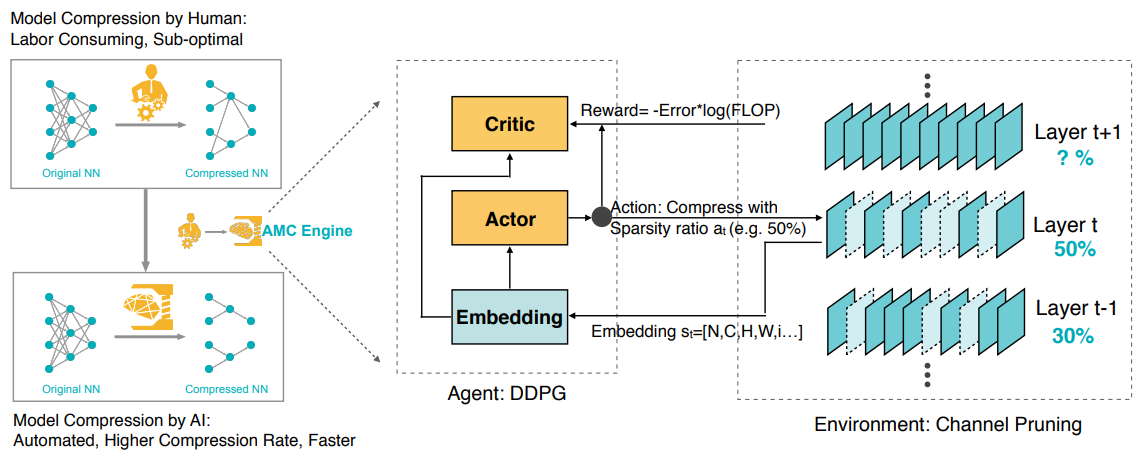
해당 논문은 PostTraining 방법으로, 먼저 Pretrained된 network(i.e. MobileNet)가 필요합니다.
강화학습 모델로는 DDPG Agent를 사용하는데, 이 Agent는 각 Layer마다 State(Weight크기, Input크기, 등) → Action(pruning비율)을 구하게 됩니다. Action Value(Pruning Ratio)를 discrete하게 가져갈 수도 있지만 {64,128,256,512}, 특정 Layer는 Pruning 비율에 굉장히 민감할 수 있기 때문에, Pruning Ratio를 더 촘촘하게 가져갈 수 있게 해주는 Continuous Action Space를 생각하게 되었고, 이를 위해서 DDPG를 사용했다고 합니다.
Layer by Layer로 Channel Pruning을 하고나서 Pruned Model이 구하게 되면, Finetuning을 하지 않은 상태에서 Accuracy를 측정하고(Finetuning하게 되면 시간이 오래 걸리며, Finetuning을 하지 않은 Accuracy를 사용하여도, 어느정도 Representation이 보전되어 큰 문제가 없다고 합니다), FLOP(연산량)도 측정하여 우리가 원하는 Reward Function을 설계하여, 해당 Reward를 높이는 방향으로 DDPG Agent를 학습시킵니다.
URL: https://arxiv.org/abs/1802.03494
Code: https://github.com/mit-han-lab/AMC
1. Related Works

AutoML 관련(Reinforcement, Genetic알고리즘 기반).
NAS → aims to search the transferable network blocks
NT → proposed to speed up the exploration via network transformation
N2N → integrated reinforcement learning into channel selection.
2. Algorithm
이 논문에서는 DDPG Agent를 통해서 각 Layer의 Pruning Ratio를 구하게 되고, 이 Ratio를 기반으로 Channel Pruning(Structured Pruning)을 수행하게 됩니다. 구해지는 Pruning Ratio가 Continuous 값인데, 이에 기반하여 Channel 수 몇개를 없앨 것인지? 또 한 Layer에서 3개의 채널을 없앤다고 하였을 때, 어떠한 조합을 없앨 것인지에 대해서는 아직은 모르겠고, 코드를 살펴봐야 할 것 같습니다.
또한 해당 논문에 코드를 이해하기 위해서는 일단 RL DDPG에 대해서도 이해를 하고 있어야 합니다. 일단 해당 논문에서 나열된 알고리즘은 주로 강화학습에 대한 설명 밖에 없습니다.
2.1 State Space
For each layer t, we have 11 features that characterize the state st:
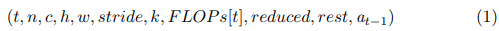
where t is the layer index, the dimension of the kernel is n×c×k×k, and the input is c × h × w. FLOP s[t] is the FLOPs of layer L_t. Reduced is the total number of reduced FLOPs in previous layers. Rest is the number of remaining FLOPs in the following layers. Before being passed to the agent, they are scaled within [0, 1].
2.2 Action Space
Most of the existing works use discrete space as coarse grained action space (e.g., {64, 128, 256, 512} for the number of channels). However, we observed that model compression is very sensitive to sparsity ratio and requires fine-grained action space, leading to an explosion of the number of discrete actions. Such large action spaces are difficult to explore efficiently[32]. As a result, we propose to use continuous action space a ∈ (0, 1], which enables more fine-grained and accurate compression.
2.3 Reward Function
Error(성능 저하), FLOPs, #Param을 모두 낮추는 방향으로 Reward를 정의할 수 있습니다.

논문에는 이와 같은 방법 말고도 "Resource-Constrained Compression"에 맞는 Reward Function도 소개 하고 있으니, 참고 바랍니다.
2.4 DDPG Agent
Our actor network µ has two hidden layers, each with 300 units. The final output layer is a sigmoid layer to bound the actions within (0, 1). Our critic network Q also had two hidden layers, both with 300 units. Actions arr included in the second hidden layer. We use τ = 0.01 for the soft target updates and train the network with 64 as batch size and 2000 as replay buffer size. Our agent first explores 100 episodes with a constant noise σ = 0.5, and then exploits 300 episodes with exponentially decayed noise σ.
The agent receives an embedding state s_t of layer L_t from the environment and then outputs a sparsity ratio as action a_t. The underlying layer is compressed with at (rounded to the nearest feasible fraction) using a specified compression algorithm (e.g., channel pruning). Then the agent moves to the next layer L_t+1, and receives state s_t+1. After finishing the final layer L_T , the reward accuracy is evaluated on the validation set and returned to the agent. For fast exploration, we evaluate the reward accuracy without fine-tuning, which is a good approximation for fine-tuned accuracy.


